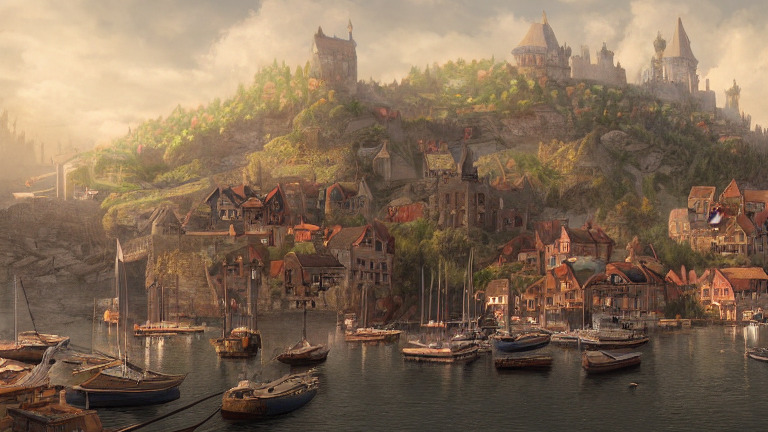
Stable Diffusionはオープンソースで各個人がローカル環境で無償利用できるとはいえ、特別な環境ではないもののNVIDIA製のGPU搭載パソコン、大容量メモリ領域などの導入ハードルは高いといえます。ただし、Googleが提供している「Colaboratory(略:colab)」を利用すれば、初期費用の投資なく比較的簡単に導入できます。今回はGoogle colaboratory でstable Diffusionを動かし、作成した画像はGoogleドライブ内に自動的に格納できるようにしてみたコードを記載しておきます。私自身はPythonド素人なので間違っていたらすみませんです。
ちなみにオープンソースなので、しばらくすると色々な方々が優れたツールを作成してくれることでしょう。
Google Colaboratory上でStable Diffusionを動かすコード
とりあえず、Google Colaboratory上でStable Diffusionを動かすコードが以下です。
いろいろなサイトを参考にして作成しています。間違っていたらゴメンナサイですね。
# ライブラリのインストール
!pip install diffusers==0.3.0 transformers scipy ftfy
# アクセス・トークン設定
YOUR_TOKEN="****(ここにHugging Faceで発行したトークンを記述)****"
# パイプライン構築
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
pipe.to("cuda")
#Google driveに接続
from google.colab import drive
drive.mount('/content/drive')
#Google driveのフォルダーを指定
import os
os.chdir('/content/drive/MyDrive/AI_Image')import datetime
import pytz
import re
import random
import math
import torch
from torch import autocast
from IPython.display import display
#◆呪文◆
prompt = "A digital illustration of a Medieval town with large harbor, vessel, trending in artstation, detailed, fantasy, Unreal Engine"
#ファイル名から余計な文字を除去(ここでは不使用!)
#filename = re.sub(r'[\\/:*?"<>|,]+', '', prompt).replace(' ','_')
#日時を取得
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
date = now.strftime('%Y%m%d-%H%M%S')
#◆描画サイズを指定◆ W512*H512がデフォルト推奨 横長W768*H512 16の倍数以外、768以上はエラー
W=768
H=512
#◆選択◆ → SEED値ランダム:1 or 固定:2 ◆
a = 1
#◆画像数◆
number=5
for i in range(number):
if a == 1:
seed = random.randrange(0, 4294967295, 1)
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
else:
#必要に応じてSEED値を調整(◆選択の箇所で固定:1 と指定すること)
seed = 3412833592
scale = math.floor((random.uniform(8.0, 9.5))*100)/100
steps = random.randrange(140, 150, 1)
with autocast("cuda"):
generator = torch.Generator("cuda").manual_seed(seed)
image = pipe(prompt, height=H, width=W, guidance_scale=scale, num_inference_steps=steps, generator=generator)["sample"][0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
image.save(date + "【" + str(i+1) + "】.png")
#テキストファイル作成
if i == 0:
txt_data = "prompt値= " + prompt + "\n"
txt_data = txt_data + date + "【" + str(i+1) + "】SEED値: " + str(seed) + " scale値: " + str(scale) + " steps値: " +str(steps) + "\n"
else:
txt_data = txt_data + date + "【" + str(i+1) + "】SEED値: " + str(seed) + " scale値: " + str(scale) + " steps値: " +str(steps) + "\n"
f = open(date + ".txt","w")
f.write(txt_data)
f.close()画像生成のコードのところでは、オリジナルに改変しています。
- コード内の◆***◆の箇所は、出力処理をする前に値を確認し、意図した出力ができるように調整をする。
※11行目のPrompt いわゆる呪文
※20行目の描画サイズ 出力する画像の縦と横サイズ
※24行目の選択 SEED値(scale値、steps値)をランダムで生成するか、固定値で生成するか
※28行目の画像数 出力する画像数を指定 - 画像ファイル(png)を出力と同時に、画像生成した時のprompt、SEED値、scale値、steps値をテキストファイルで出力。
- 後々どのような値で作成した画像なのか、後追いを可能とした。
ちょっとだけ下記に解説しておりますので参考まで。
Stable Diffusion導入手順
手順は3段階。難しいことは抜きにしてやっていきましょう。
1. Hugging Faceのトークンを発行する
2. Google ColaboratoryでStable Diffusionを使う準備をする
3. Stable Diffusionで画像を生成する
Hugging Faceのトークンを発行
自分で構築した環境でStable Diffusionを用いるにはHugging Faceのアカウントを作成してトークンを発行する必要があります。
まずは、以下のサイトにアクセスをします。
https://huggingface.co/CompVis/stable-diffusion-v1-4
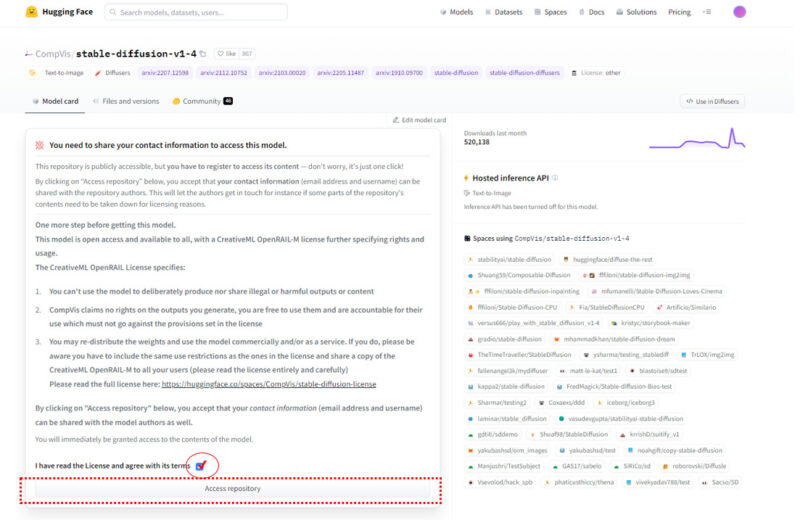
Stable Diffusionのライセンスに関する確認事項が表示されるので、(英語ですが…)よく読んでから「Access repository」をクリックします
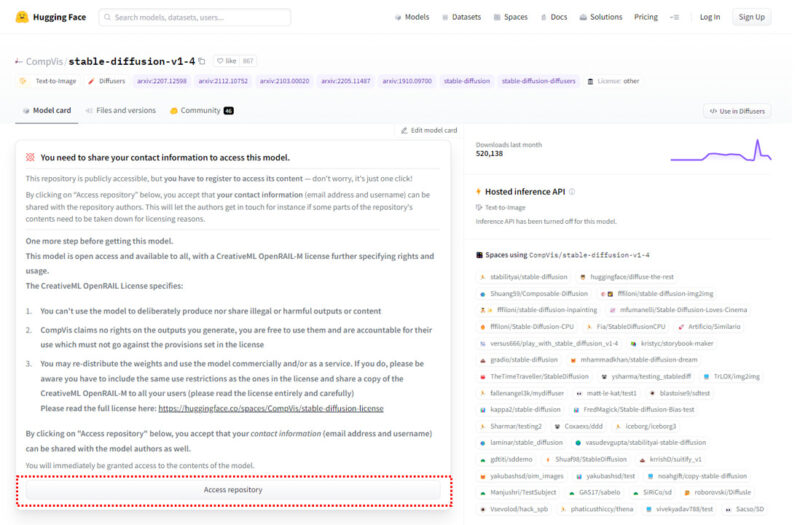
「Access repository」をクリックすると、Hugging Faceのログイン画面が表示されます。今回は新たなアカウントを作成したいので「Sign UP」をクリックです。そのあとに任意のメールアドレス(通常使用しているものでOK)を入れ、使用したいパスワードを入力して「Next」をクリック。
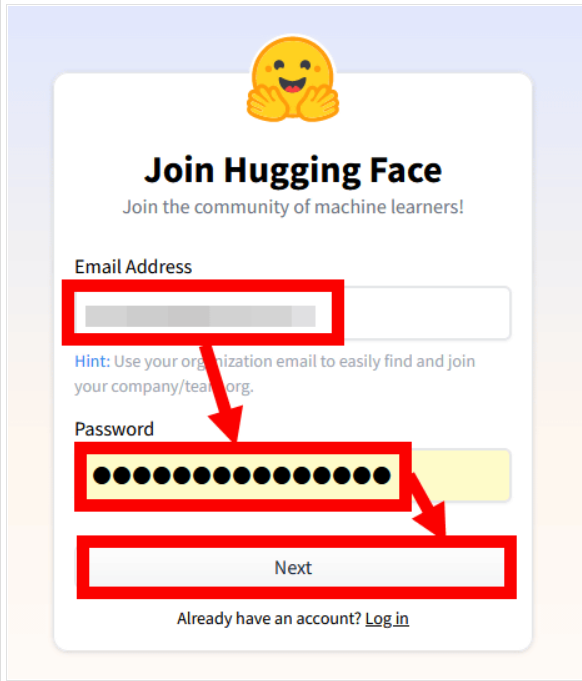
次にユーザー名(ニックネーム的なものでもOK)とフルネーム(適当なものでも大丈夫)を入力してから利用規約と行動規範を一応確認してチェックを入れて「Create Account」をクリックします。
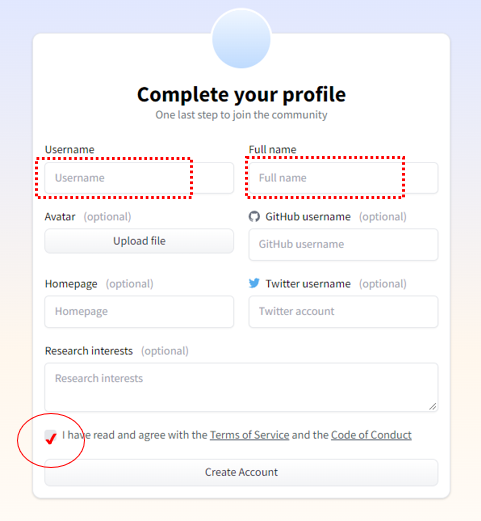
「Create Account」をクリック後、先ほど登録したメールアドレスに確認メールが届きますので、webサイトはそのままにしてMail受信箱を確認。届かない場合は、メールアドレスが誤っていたか、迷惑メールに振り分けられたか? なので確認しましょう。届いたメール本文内のURLをクリック。
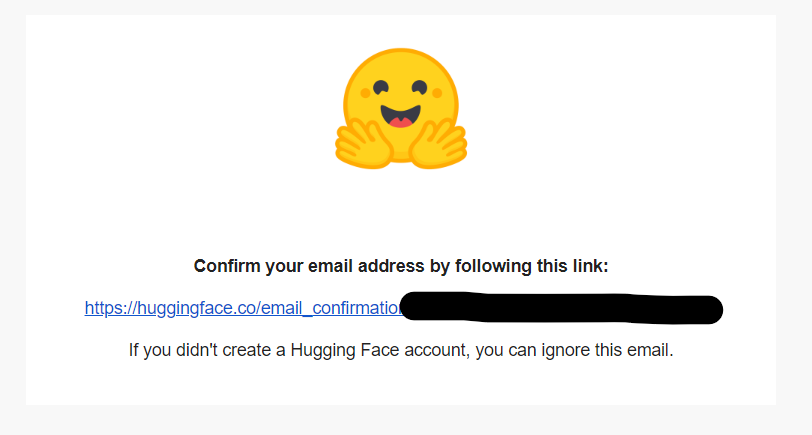
「Your email address has been verified successfully」と表示されれば、Hugging Faceのアカウント作成は完了です。
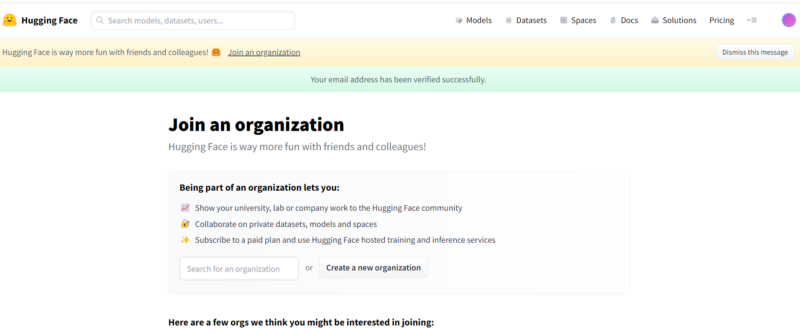
再び、Stable Diffusionのページにアクセスして、ライセンスに同意するチェックを入れてから「Access repository」をクリックします。
次にアカウントの設定登録をします。
画面右上、円形のアイコンをクリックして、その後プルダウンの中からSettingをクリック
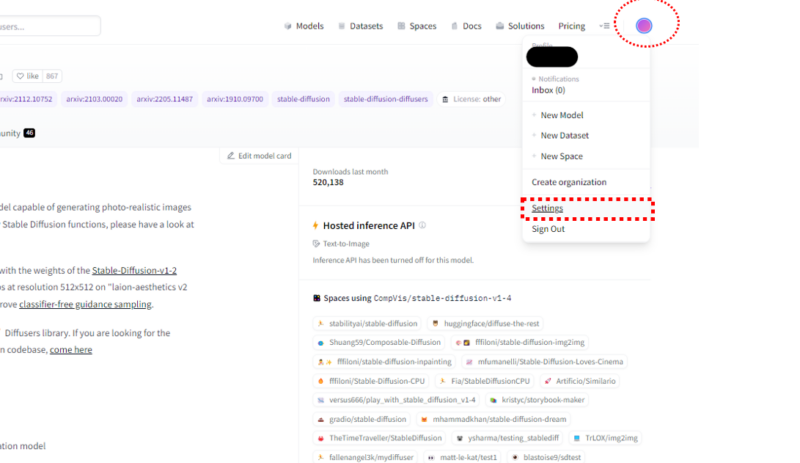
アカウントの設定画面が開いたら画面右側「Access Tokens」を選択して「New token」をクリックします。
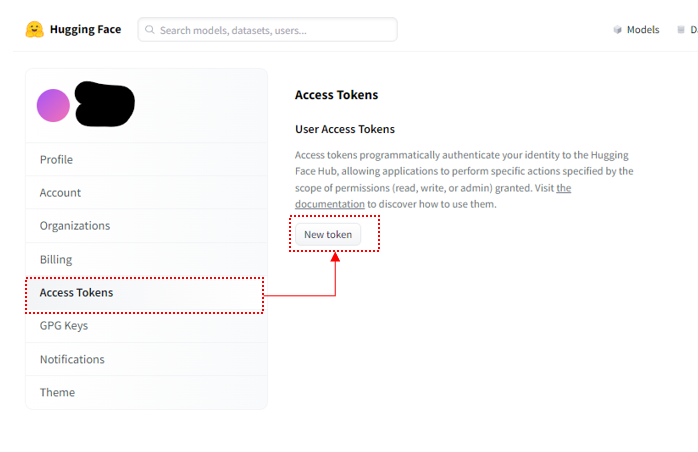
Tokenの発行画面が表示されたら名前(後ほど使用するのでメモしておいてください)を入力して「Generate a token」をクリック。
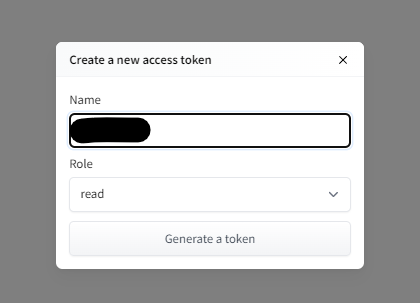
Access Tokensが発行されますので、Hugging Faceの作業は終了です。
下記の部分は後程使用するのでメモ帳などにコピペしておきましょう。
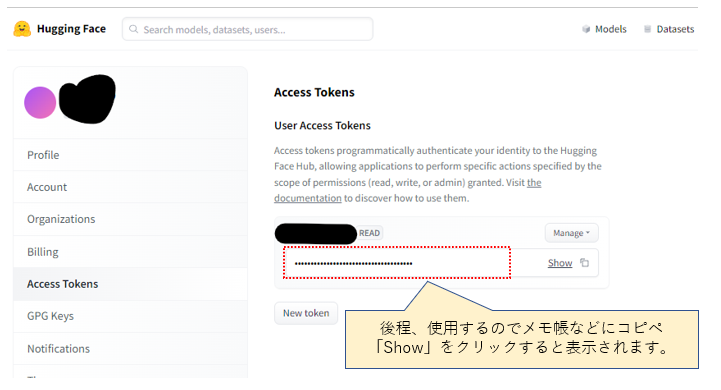
Google ColaboratoryでStable Diffusionを使う準備をする
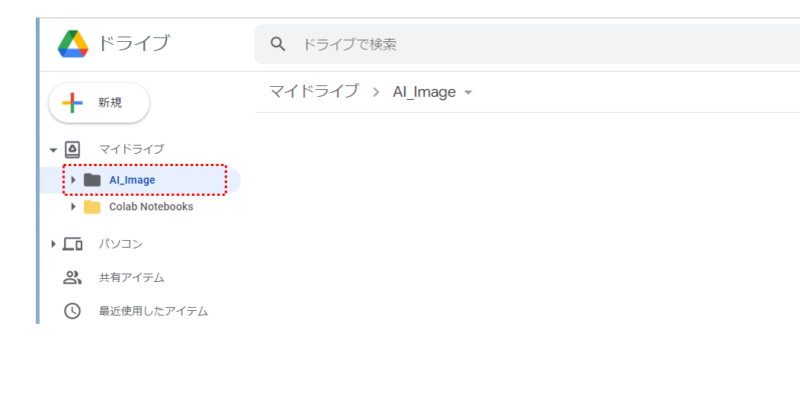
Googleドライブに画像の格納先を用意
次に生成される画像の格納先を設定します。今回はGoogleドライブ直下のマイドライブ内に「AI_Image」というフォルダーを作成しておきます。実際には任意のフォルダー名で大丈夫です。
Stable Diffusionで画像生成すると、ここのフォルダー内に自動的に格納するように設定します。
Stable Diffusionを動かす環境、Google Colaboratoryとは
Stable DiffusionはPythonが動く環境が必要なのですが、Google colaboratory(略:colab)はChrom等のブラウザ上で実行できるものです。Googleが機械学習の教育や研究用に提供しているインストール不要でPythonや機械学習・深層学習の環境を整えることが出来る無料のサービスです。Googleのアカウントさえあれば無料で利用する事が出来ます。またCPU及びGPU(1回12時間)の環境が無料で利用可能です。有料サービスもありますが、基本的には無料のもので十分に使えます。
長時間、高画質で大量に制作する場合は有料に切り替えてもよいと思います。
では、Google ColaboratoryでStable Diffusionを使用できるようにしていきましょう。まず以下にアクセスします。Colaboratoryにアクセスしたら、画面右上の「ログイン」をクリックして、自分のアカウントを選択します。その後Googleアカウントのパスワードを入力。
https://colab.research.google.com/?hl=ja
Colaboratoryにログインした時が以下のように表示されます。
下の「ノートブックを新規作成」をクリックします。
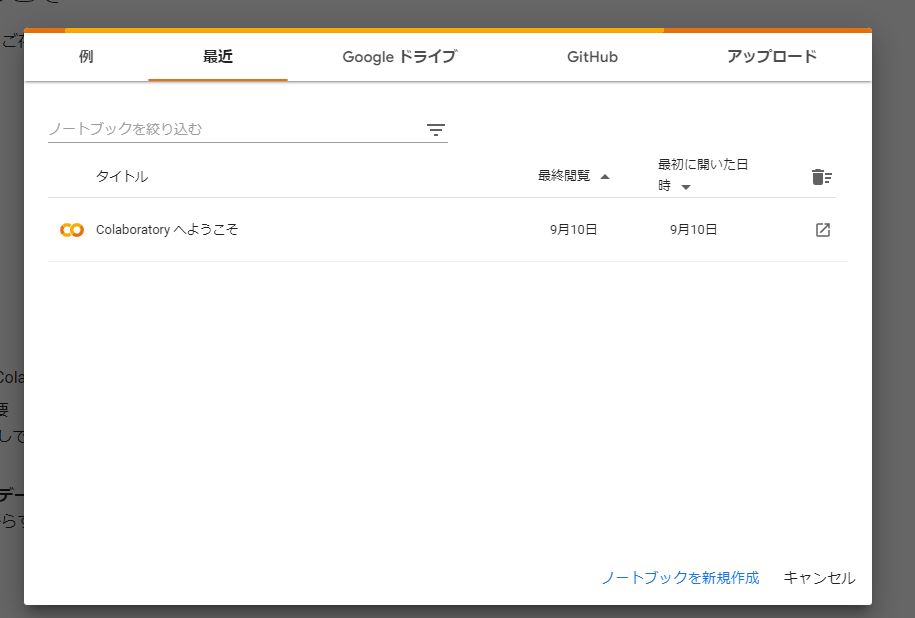
画面上部の「編集」をクリックしてから「ノートブックの設定」をクリック。
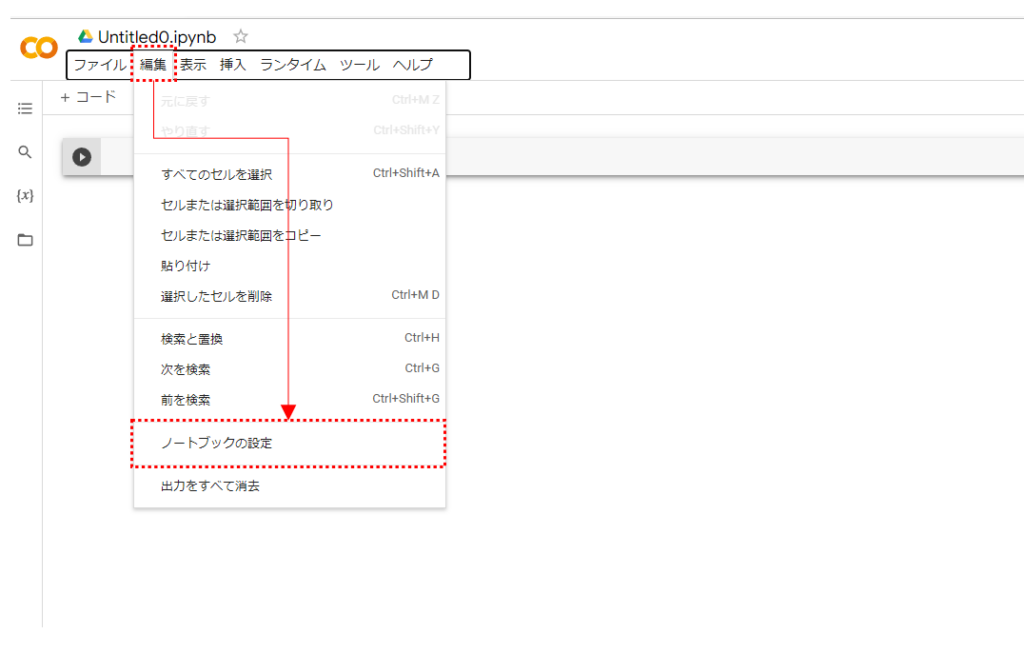
ハードウェアアクセラレータの欄で「GPU」を選択してください。
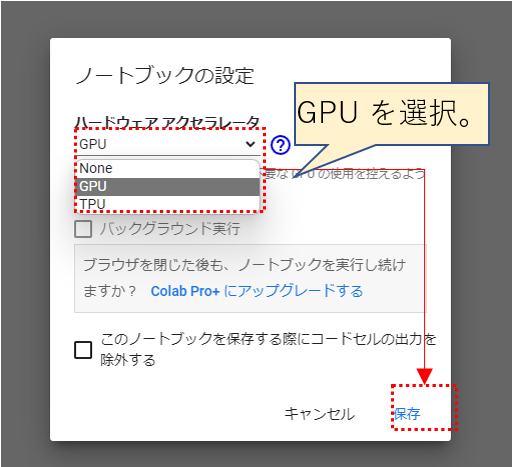
再生アイコンが左端に配置されたコマンド入力エリアにコマンドを入力することで作業を進めることが可能になります。
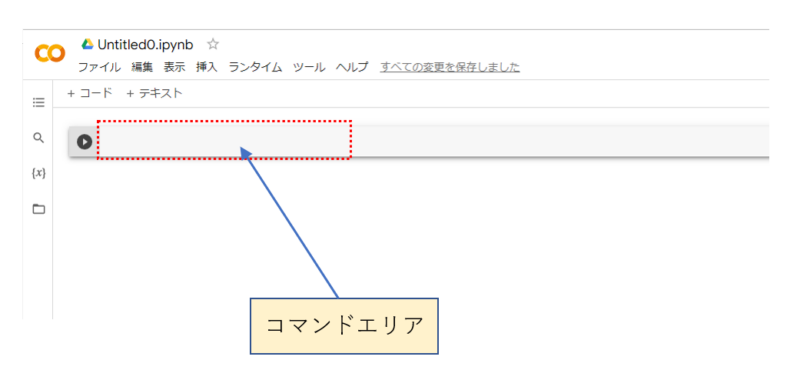
この後の手順は4つ。
1. ノートブック内にStable Diffusionをインストール
2. Hugging Faceで発行したトークンの設定
3. パイプライン構築してダウンロード開始
4. 格納先Googleドライブに接続
では、順番に。
以下のコードをコマンドエリアに記述していきます。
# ライブラリのインストール
!pip install diffusers==0.3.0 transformers scipy ftfy
# アクセス・トークン設定
YOUR_TOKEN="****(ここにHugging Faceで発行したトークンを記述)****"
# パイプライン構築
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
pipe.to("cuda")
#Google driveに接続
from google.colab import drive
drive.mount('/content/drive')
#Google driveのフォルダーを指定
import os
os.chdir('/content/drive/MyDrive/AI_Image')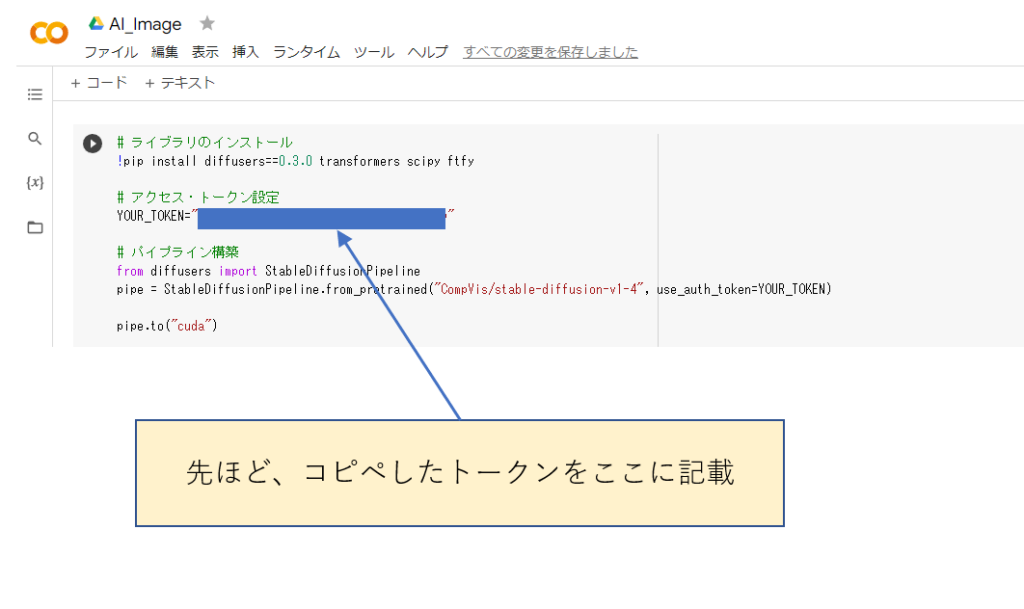
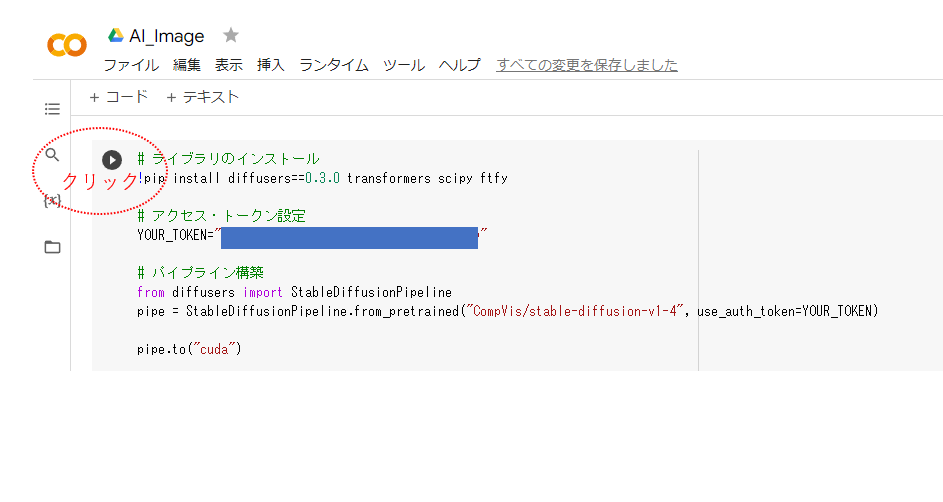
コマンドエリアにコードを記述したなら、左側の再生アイコンをクリック(=コマンド実行)します。
実行中はアイコンがくるくる回ります。途中Google ドライブへの接続確認やアカウントの確認画面が表示されるので、その都度適当なところを選択していきます。
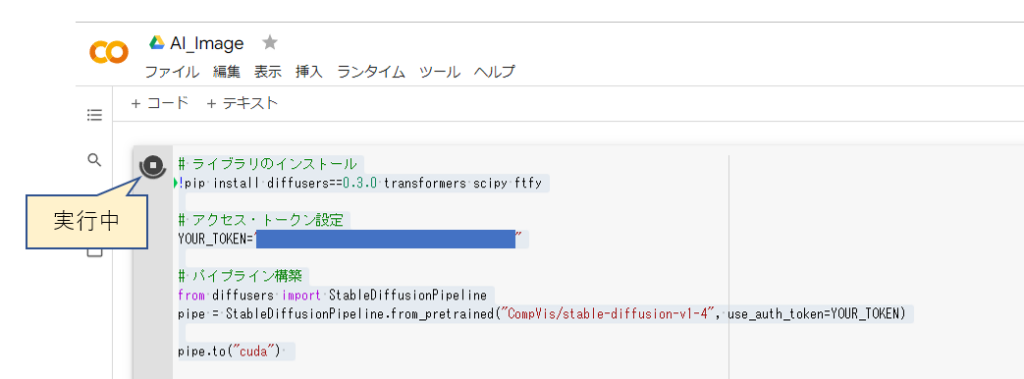
そして、実行中は以下のようにコマンドエリア下に実行内容が表示されていきます。
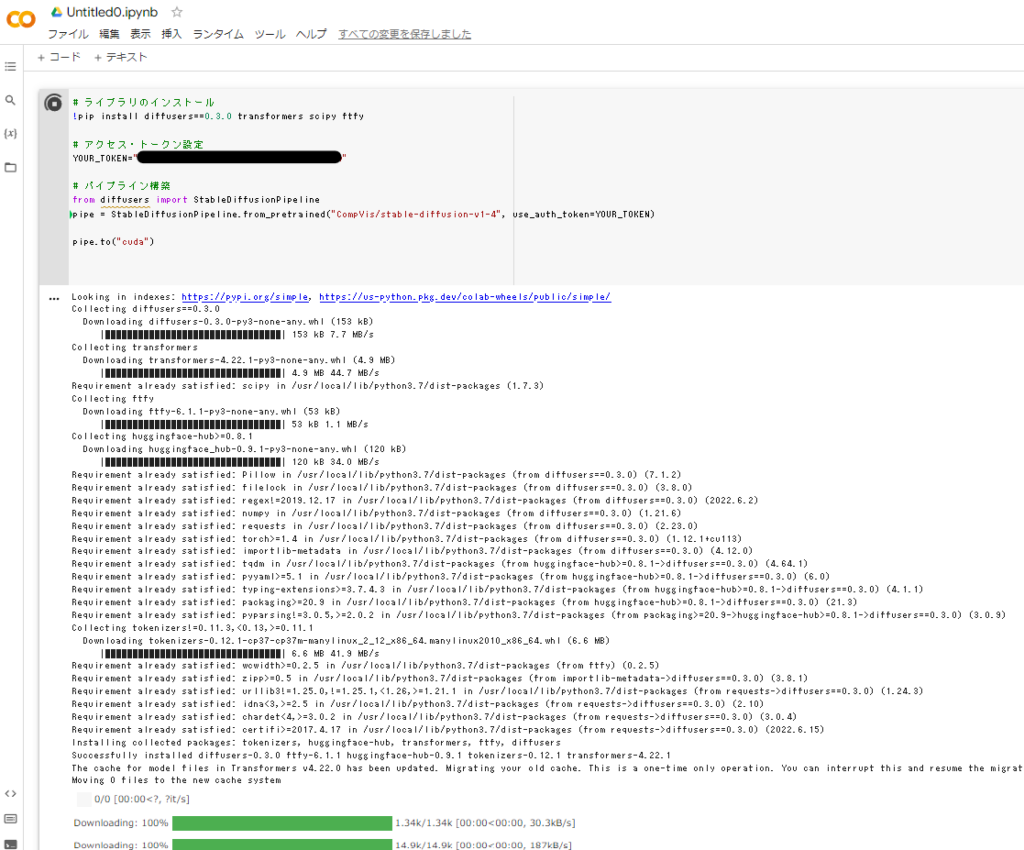
実行が終わったところ。コマンドが終了すると、再生アイコンの左側に緑色の✔が表示されます。
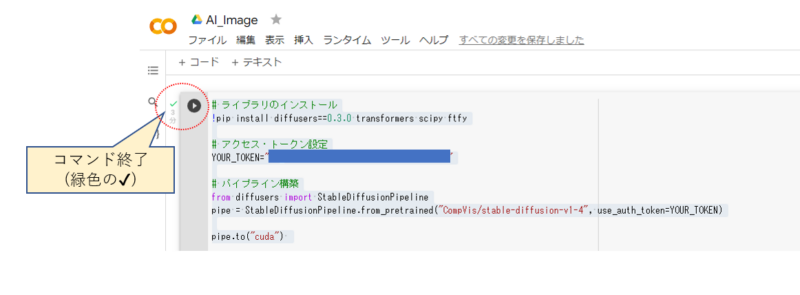
Stable Diffusionで画像を生成する
コマンドエリアを追加します。
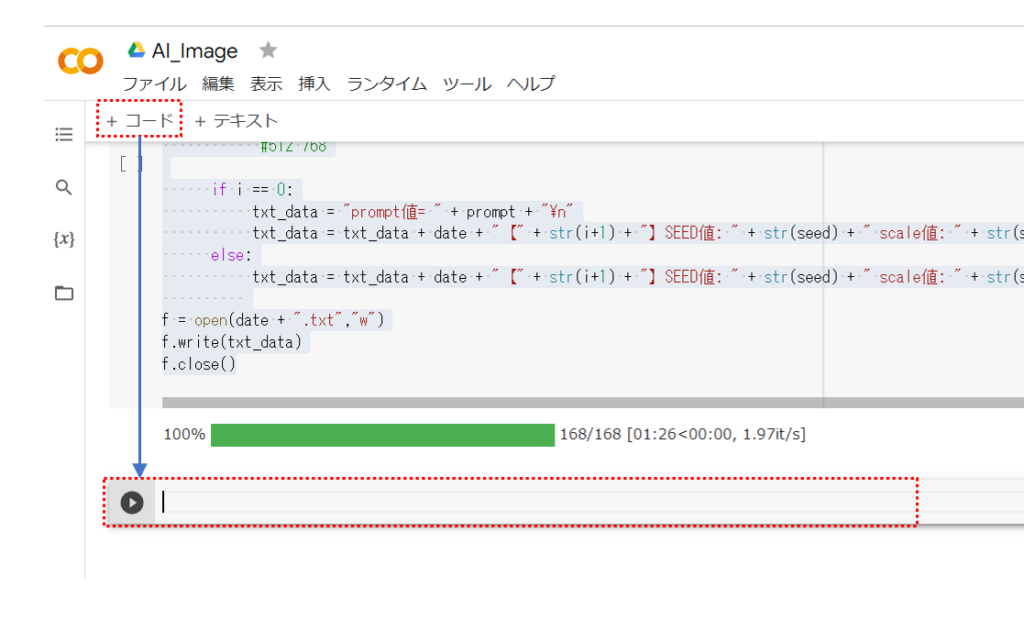
以下のコード記述します。
import datetime
import pytz
import re
import random
import math
import torch
from torch import autocast
from IPython.display import display
#◆呪文◆
prompt = "A digital illustration of a Medieval town with large harbor, vessel, trending in artstation, detailed, fantasy, Unreal Engine"
#ファイル名から余計な文字を除去(ここでは不使用!)
#filename = re.sub(r'[\\/:*?"<>|,]+', '', prompt).replace(' ','_')
#日時を取得
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
date = now.strftime('%Y%m%d-%H%M%S')
#◆描画サイズを指定◆ W512*H512がデフォルト推奨 横長W768*H512 16の倍数以外、768以上はエラー
W=768
H=512
#◆選択◆ → SEED値ランダム:1 or 固定:2 ◆
a = 1
#◆画像数◆
number=5
for i in range(number):
if a == 1:
seed = random.randrange(0, 4294967295, 1)
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
else:
#必要に応じてSEED値を調整(◆選択の箇所で固定:1 と指定すること)
seed = 3412833592
scale = math.floor((random.uniform(8.0, 9.5))*100)/100
steps = random.randrange(140, 150, 1)
with autocast("cuda"):
generator = torch.Generator("cuda").manual_seed(seed)
image = pipe(prompt, height=H, width=W, guidance_scale=scale, num_inference_steps=steps, generator=generator)["sample"][0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
image.save(date + "【" + str(i+1) + "】.png")
#テキストファイル作成
if i == 0:
txt_data = "prompt値= " + prompt + "\n"
txt_data = txt_data + date + "【" + str(i+1) + "】SEED値: " + str(seed) + " scale値: " + str(scale) + " steps値: " +str(steps) + "\n"
else:
txt_data = txt_data + date + "【" + str(i+1) + "】SEED値: " + str(seed) + " scale値: " + str(scale) + " steps値: " +str(steps) + "\n"
f = open(date + ".txt","w")
f.write(txt_data)
f.close()コマンドを実行する前に、以下の値を確認します。
◆呪文◆
promptは描画する絵を指定するテキストです。すべて英語で記述する必要があります。
◆描画サイズを指定◆
Stable Diffusionのデフォルトは512*512です。16の倍数で設定、768まで。
◆選択◆
ここではSEED値等をランダムにするか→1を指定、固定値にするか→2を指定
◆画像数◆
生成する画像の枚数
※生成画像と一緒にテキストファイルが出力されて、作成時のPrompt、SEED等の値を記録しておきます。
